Leonardo
Ramirez Moreno
Senior Data Engineer with 7+ years building remote data platforms for analytics, reporting, and AI/ML workloads. Hands-on across the full stack: ETL pipelines, dimensional warehouse modeling, Kubernetes orchestration, and data quality validation. Currently freelancing through Datatent Ltd, delivering cloud-native platforms for European clients, every engagement built from scratch.
Ingeniero de Datos Senior con más de 7 años construyendo plataformas de datos remotas para analítica, reporting y cargas de trabajo de IA/ML. Experiencia full-stack: pipelines ETL, modelado de warehouse dimensional, orquestación en Kubernetes y validación de calidad de datos. Actualmente freelance a través de Datatent Ltd, entregando plataformas cloud-nativas para clientes europeos, todos los proyectos construidos desde cero.
02: SummaryResumen
Data engineer with 7+ years delivering production platforms from scratch: ingestion pipelines, dimensional data models, Kubernetes-native orchestration, and data quality tooling, across AWS, Azure, and Microsoft Fabric. Spent 3.5 years at Cafeto Software (Optimizely) leading a PostgreSQL/Airflow to Snowflake/dbt/Argo Workflows migration and building a Python + React observability tool that reduced data errors by 15%. Currently freelancing through Datatent Ltd, building analytics stacks for European clients in education, financial services, manufacturing ERP, and legal case management, every engagement built from scratch.
Ingeniero de datos con más de 7 años entregando plataformas en producción desde cero: pipelines de ingesta, modelos dimensionales, orquestación nativa en Kubernetes y herramientas de calidad de datos, en AWS, Azure y Microsoft Fabric. Pasé 3.5 años en Cafeto Software (Optimizely) liderando una migración de PostgreSQL/Airflow a Snowflake/dbt/Argo Workflows y construyendo una herramienta de observabilidad en Python + React que redujo los errores de datos en un 15%. Actualmente freelance a través de Datatent Ltd, construyendo stacks de analítica para clientes europeos en educación, servicios financieros, ERP de manufactura y gestión de casos legales, todos los proyectos construidos desde cero.
03: ExperienceExperiencia
PresentPresente
Insurance
- Snowflake data platform built from scratch and delivered in 4 months, with dlt incremental ingestion from 30+ MSSQL tables (Qube case management), Bronze/Silver/Gold medallion architecture, 56 dbt models (4 facts, 8 dimensions); enabled the company's first self-serve analytics layer from a previously siloed system.
- Plataforma Snowflake construida desde cero y entregada en 4 meses, con ingesta incremental vía dlt desde más de 30 tablas MSSQL (gestión de casos Qube), arquitectura medallón Bronze/Silver/Gold, 56 modelos dbt (4 tablas de hechos, 8 dimensiones); habilitó la primera capa de analítica self-service de la empresa desde un sistema previamente aislado.
- Provisioned Azure AKS infrastructure with Terraform; Kubernetes-native orchestration via Argo Workflows CronWorkflows (6-hour cadence); full CI/CD pipeline (lint → test → Docker build → ACR push → dev → prod).
- Infraestructura Azure AKS aprovisionada con Terraform; orquestación nativa en Kubernetes con CronWorkflows de Argo Workflows (cadencia de 6 horas); pipeline CI/CD completo (lint → test → build Docker → push ACR → dev → prod).
- Secrets via Azure Key Vault + External Secrets Operator, Snowflake private-key authentication; dbt docs served on Kubernetes for self-service lineage.
- Secretos gestionados con Azure Key Vault + External Secrets Operator y autenticación Snowflake con clave privada; dbt docs servidos en Kubernetes para linaje self-service.
Services
- Bronze-Silver-Gold ETL pipeline on Microsoft Fabric built from scratch in 4 months, with 47 Python/PySpark ingestion notebooks handling 50+ Excel files from 15+ legal entities across 5 operating companies, including fuzzy header detection, date extraction, and per-file audit logging.
- Pipeline ETL Bronze-Silver-Gold en Microsoft Fabric construido desde cero en 4 meses, con 47 notebooks Python/PySpark gestionando más de 50 archivos Excel de más de 15 entidades legales en 5 grupos empresariales, incluyendo detección difusa de cabeceras, extracción de fechas y registro de auditoría por archivo.
- Built a 3-tier contra-entity matching engine (seed mappings → normalised exact matching → fuzzy similarity) with a closed-loop SharePoint review workflow via Microsoft Graph API, resolving company identity ambiguity across independently operated entities.
- Motor de coincidencia de contra-entidades en 3 niveles (mapeos semilla → coincidencia exacta normalizada → similitud difusa) con flujo de revisión de cierre de ciclo en SharePoint vía Microsoft Graph API, resolviendo la ambigüedad de identidad entre entidades operadas de forma independiente.
- Replaced a fully manual reporting process; platform surfaced data quality errors that had been undetected in the previous workflow.
- Reemplazó un proceso de reporting completamente manual; la plataforma detectó errores de calidad de datos que habían pasado desapercibidos en el flujo de trabajo anterior.
- Built end-to-end data platform from zero, with 17 Python ingestion pipelines (REST APIs, UK government portals, CRM, document scraping with Selenium + PDF/DOCX parsing) → AWS S3 → Snowflake across a 3-tier medallion architecture: 123 dbt models across 14 source domains, 7 reporting marts, normalising 30,000+ UK schools.
- Plataforma de datos end-to-end construida desde cero, con 17 pipelines de ingesta en Python (REST APIs, portales gubernamentales UK, CRM, scraping de documentos con Selenium + parseo PDF/DOCX) → AWS S3 → Snowflake en arquitectura medallón de 3 niveles: 123 modelos dbt en 14 dominios de fuente, 7 marts de reporting, normalizando más de 30.000 escuelas UK.
- Provisioned full AWS stack via Terraform (VPC, EKS, IAM/IRSA, KMS, ALB); Argo Workflows for pipeline scheduling; External Secrets Operator for secrets; OpenMetadata for data discovery and lineage; automated CI/CD with GitHub Actions (SQLFluff lint, dbt compile, manifest-based state deferral for targeted tests, ECR image push).
- Stack AWS completo aprovisionado con Terraform (VPC, EKS, IAM/IRSA, KMS, ALB); Argo Workflows para scheduling de pipelines; External Secrets Operator para secretos; OpenMetadata para descubrimiento y linaje; CI/CD automatizado con GitHub Actions (lint SQLFluff, dbt compile, deferral por manifiesto para tests focalizados, push a ECR).
- Built the AI product data layer: 19 dbt models in AI_ASSISTANT_ODS powering a production OpenAI education assistant, with nightly sync pipelines from Snowflake to Azure SQL and from S3 documents to Azure Blob Storage for AI search indexing.
- Construyó la capa de datos del producto IA: 19 modelos dbt en AI_ASSISTANT_ODS que impulsan un asistente educativo OpenAI en producción, con pipelines de sincronización nocturna de Snowflake a Azure SQL y de documentos S3 a Azure Blob Storage para indexación con AI Search.
ERP
- Sole data engineer, built the company's entire analytics foundation from zero: ADF ingestion pipelines for 4 heterogeneous source systems (Microsoft Business Central REST API with fiscal-cursor Until loops, LV ERP, SAP, Planful), all landing into Azure SQL.
- Único ingeniero de datos, construyó toda la base de analítica de la empresa desde cero: pipelines ADF para 4 sistemas de origen heterogéneos (REST API Business Central con bucles Until por cursor fiscal, LV ERP, SAP, Planful), todos aterrizando en Azure SQL.
- Designed a 63-model dbt project (staging → transform → reporting) with star schema using dbt_utils.union_relations to consolidate 3 disparate ERP schemas across 3 legal entities (Collingwood, Indigo, NOBILE), unifying 1.4M+ production records (920K sales + 140K purchase transactions).
- Diseñó un proyecto dbt de 63 modelos (staging → transform → reporting) con esquema en estrella usando dbt_utils.union_relations para consolidar 3 esquemas ERP distintos en 3 entidades legales (Collingwood, Indigo, NOBILE), unificando más de 1,4M de registros de producción (920K ventas + 140K compras).
- Produced formal data quality assessment with entity-level reliability verdicts and gap-fill proposals; governed dashboard readiness, preventing go-live on data that silently undercounted revenue by 60% of rows due to a structural API limitation.
- Elaboró una evaluación formal de calidad de datos con veredictos de fiabilidad por entidad y propuestas de mejora; gobernó la preparación de dashboards, evitando el lanzamiento con datos que infracontaban ingresos en el 60% de las filas por una limitación estructural de la API.
Dec 2024
3.5 years
- Built a custom Python + React data validation and observability tool to monitor quality metrics in real time, reducing null and incorrect values by 15% across production pipelines.
- Construyó una herramienta personalizada de validación y observabilidad de datos en Python + React para monitorizar métricas de calidad en tiempo real, reduciendo nulos y valores incorrectos un 15% en pipelines de producción.
- Led migration from PostgreSQL/Airflow/stored procedures to Snowflake/Argo Workflows/dbt, turning monolithic transformation logic into modular, version-controlled dbt models running on Kubernetes-native orchestration.
- Lideró la migración de PostgreSQL/Airflow/stored procedures a Snowflake/Argo Workflows/dbt, convirtiendo lógica de transformación monolítica en modelos dbt modulares y versionados sobre orquestación nativa de Kubernetes.
- Led Data Operations: ensured reliability and SLA compliance across business-critical analytics pipelines; managed incident response, root cause analysis, and continuous improvement for production data quality issues.
- Lideró Operaciones de Datos: garantizó fiabilidad y cumplimiento de SLA en pipelines de analítica críticos para el negocio; gestionó respuesta a incidentes, análisis de causa raíz y mejora continua de problemas de calidad en producción.
- Collaborated cross-functionally to define data quality standards and deliver structured remediation plans.
- Colaboró con equipos multifuncionales para definir estándares de calidad de datos y entregar planes de remediación estructurados.
Jun 2021
2 years
- Technical lead for automation and data implementation within an enterprise Operational Excellence Center at one of Latin America's largest banks.
- Líder técnico de automatización e implementación de datos en un Centro de Excelencia Operacional de uno de los bancos más grandes de Latinoamérica.
- Designed transactional databases for virtual assistants and automated decision workflows.
- Diseñó bases de datos transaccionales para asistentes virtuales y flujos de decisión automatizados.
- Led high-complexity production deployments, peer reviews, and architecture governance for reliable automation solutions.
- Lideró despliegues en producción de alta complejidad, revisiones entre pares y gobernanza de arquitectura para soluciones de automatización fiables.
3 years
- Designed, developed, documented, and supported production automation solutions with monitoring, change control, and consolidated reporting.
- Diseñó, desarrolló, documentó y soportó soluciones de automatización en producción con monitorización, control de cambios y reporting consolidado.
- Built a high-volume automated transaction system executing parallel workloads across multiple robots without a centralised orchestrator.
- Construyó un sistema de transacciones automatizadas de alto volumen ejecutando cargas de trabajo en paralelo en múltiples robots sin un orquestador centralizado.
04: Personal LabLaboratorio Personal
End-to-end data platform for European shopping center operators, built publicly to demonstrate the architecture and engineering patterns used across client engagements. Ingests real public APIs (weather, public holidays, flight data) plus a synthetic visitor-traffic simulator into an AWS S3 lakehouse, processes data through AWS Glue (PySpark) and dbt on Athena, and exposes marts as a FastAPI data product. Orchestrated with Argo Workflows on EKS; infrastructure provisioned with Terraform.
Plataforma de datos end-to-end para operadores de centros comerciales europeos, construida públicamente para demostrar los patrones de arquitectura e ingeniería usados en proyectos de clientes. Ingesta APIs públicas reales (clima, festivos, vuelos) junto con un simulador de tráfico de visitantes hacia un lakehouse en S3, procesa los datos con AWS Glue (PySpark) y dbt sobre Athena, y expone los marts como producto de datos FastAPI. Orquestado con Argo Workflows en EKS; infraestructura con Terraform.
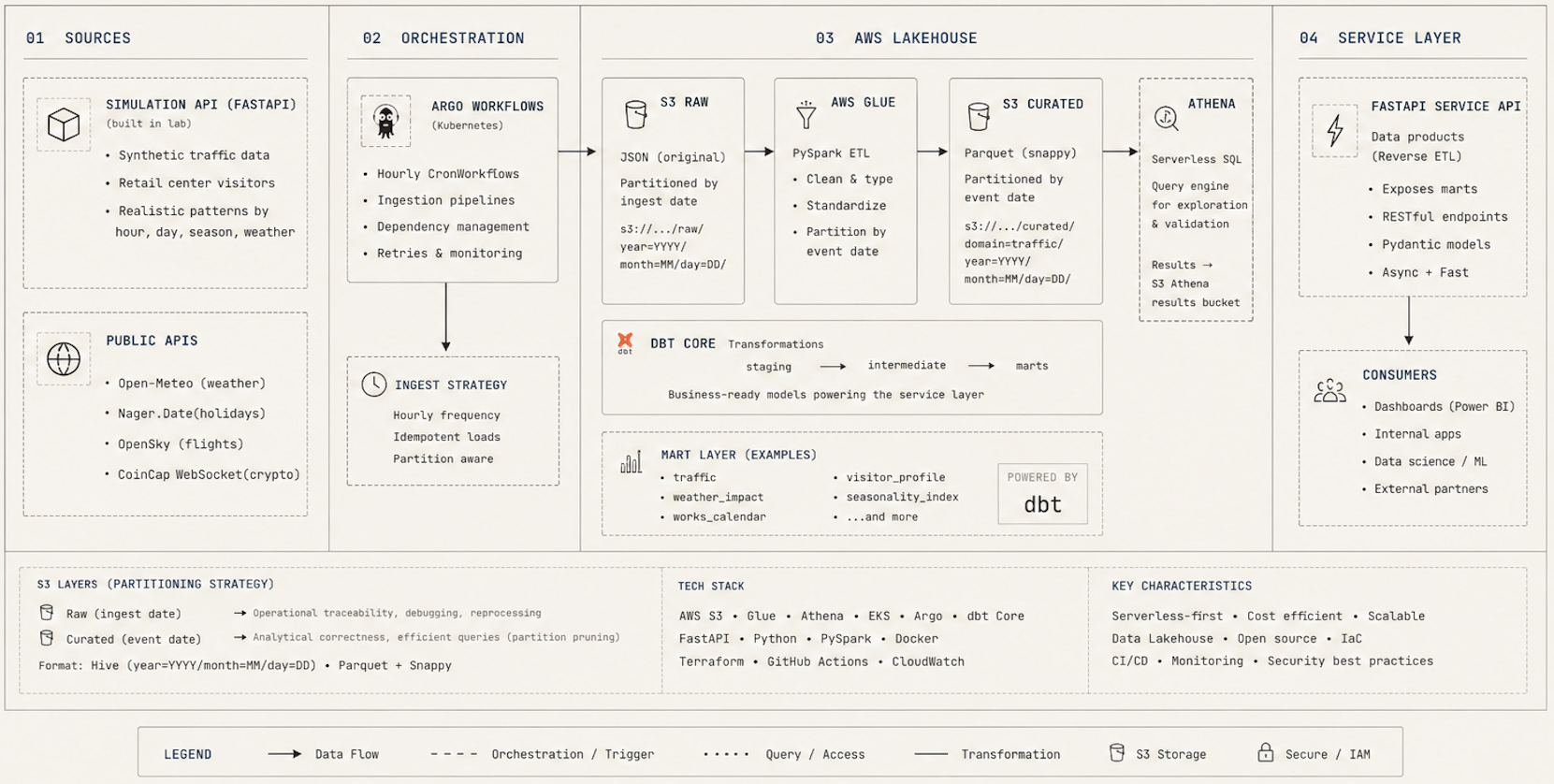

05: Selected ProjectsProyectos Destacados
Full-stack internal tool built to give the data team real-time visibility into pipeline health. Monitored quality metrics (nulls, duplicates, referential integrity, value distributions) across production tables in Snowflake, surfaced anomalies in a React dashboard, and triggered alerts before issues reached downstream consumers.
Herramienta interna full-stack construida para dar al equipo de datos visibilidad en tiempo real del estado de los pipelines. Monitorizaba métricas de calidad (nulos, duplicados, integridad referencial, distribuciones de valores) en tablas de producción en Snowflake, mostraba anomalías en un dashboard React y lanzaba alertas antes de que los problemas llegaran a los consumidores downstream.
- Reduced null and incorrect values by 15% across production data assets.
- Redujo nulos y valores incorrectos en un 15% en los activos de datos de producción.
- Python backend computed validation checks on schedule; React frontend gave the team a live quality scorecard without querying Snowflake directly.
- Backend en Python ejecutaba checks de validación programados; frontend en React ofrecía un scorecard de calidad en vivo sin necesidad de consultar Snowflake directamente.
- Replaced ad-hoc SQL checks, enabling the team to respond to quality regressions proactively rather than reactively.
- Reemplazó checks SQL ad-hoc, permitiendo al equipo responder a regresiones de calidad de forma proactiva.
The hardest data problem in the Financial Services platform: the same company appearing as both Customer and Supplier across 5 independent operating companies, each with different naming conventions, legal suffixes, and abbreviations. Built a 3-tier resolution engine combining deterministic rules with fuzzy matching and a human-in-the-loop review workflow.
El problema de datos más complejo de la plataforma de Servicios Financieros: la misma empresa apareciendo como Cliente y Proveedor en 5 grupos empresariales independientes, cada uno con convenciones de nombre, sufijos legales y abreviaciones distintos. Motor de resolución en 3 niveles que combina reglas deterministas, similitud difusa y un flujo de revisión humana en el ciclo.
- Tier 1, seed mappings: known matches hardcoded as ground truth, applied first with zero computational cost.
- Nivel 1, mapeos semilla: coincidencias conocidas como verdad absoluta, aplicadas primero con coste computacional cero.
- Tier 2, normalised exact matching: strips legal suffixes (Ltd, LLC, GmbH, Plc), punctuation, and abbreviations before comparing, catching the majority of matches automatically.
- Nivel 2, coincidencia exacta normalizada: elimina sufijos legales (Ltd, LLC, GmbH, Plc), puntuación y abreviaciones antes de comparar, resolviendo la mayoría de coincidencias de forma automática.
- Tier 3, fuzzy similarity: cross-join with ≥40% similarity threshold for edge cases; unresolved pairs exported to Excel and uploaded to SharePoint via Microsoft Graph API for business review; approved matches automatically imported on the next pipeline run.
- Nivel 3, similitud difusa: producto cruzado con umbral de similitud ≥40% para casos límite; pares no resueltos exportados a Excel y subidos a SharePoint vía Microsoft Graph API para revisión de negocio; las coincidencias aprobadas se importan automáticamente en la siguiente ejecución del pipeline.
Led the migration of a production data platform from PostgreSQL/Airflow/stored procedures to Snowflake/dbt/Argo Workflows, re-engineering monolithic SQL stored procedures into modular, version-controlled dbt models and replacing Airflow with Kubernetes-native Argo Workflows, improving reliability, testability, and developer velocity.
Lideró la migración de una plataforma de datos en producción de PostgreSQL/Airflow/stored procedures a Snowflake/dbt/Argo Workflows, con re-ingeniería de procedimientos SQL monolíticos en modelos dbt modulares y versionados, y sustitución de Airflow por Argo Workflows nativo en Kubernetes, mejorando fiabilidad, testabilidad y velocidad de desarrollo.
- Decomposed stored procedures into layered dbt models (staging → transform → reporting) with documented column contracts and dbt tests at every layer.
- Descompuso stored procedures en modelos dbt en capas (staging → transform → reporting) con contratos de columnas documentados y tests dbt en cada capa.
- Argo Workflows replaced Airflow: Kubernetes-native execution, no separate scheduler infrastructure, event-driven triggers for pipeline chaining.
- Argo Workflows sustituyó a Airflow: ejecución nativa en Kubernetes, sin infraestructura de scheduler adicional, triggers orientados a eventos para encadenamiento de pipelines.
- Migration improved SLA compliance and eliminated a class of silent failures caused by untestable stored procedure logic.
- La migración mejoró el cumplimiento de SLA y eliminó una clase de fallos silenciosos causados por lógica de stored procedures no testeable.